Guy Tel-Zur, March 20, 2024
In this blog post I will explain what is the roofline model, its importance and how to measure the achieved performance of a computer program, and how it is compared to the peak theoretical performance of the computer. According to this model we measure the performance of a computer program as the ratio between the computational work done divided by the memory traffic that was required to allow this computation. This ratio is called the arithmetic intensity and it is measured in units of (#floating-point operations)/(#Byte transferred between the memory and the CPU). An excellent paper describing the roofline mode is given in [1] and it cover page is shown in next figure.

As a test case I used the famous stream benchmark. At its core stream does the following computational kernel:
c[i] = a[i] + b[i];
Where a, b and c are large arrays. The computational intensity in this case consists of 1 floating point operation (‘+’) and 3 data movement (read a and b from memory and write back c). if a, b, and c are of type float, it means that each element contains 4bytes and the total the data movement is 12bytes, therefore the computational intensity is 1/12 which is about 0.083. We will test this prediction later on. The official stream benchmark can be downloaded from [3]. However, for my purpose this code seems to be too-complex and also according to [2] the roofline results that it produces may be miss-leading. Therefore, I wrote a simple stream code myself. The reference code is enclosed in the code section below.
#include <stdio.h>
#include <stdlib.h> // for random numbers
#include <omp.h> // for omp_get_wtime()
#define SIZE 5000000 // size of arrays
#define REPS 1000 // number of repetitions to make the program run longer
float a[SIZE],b[SIZE],c[SIZE];
double t_start, t_finish, t;
int i,j;
int main() {
// initialize arrays
for (i=0; i<SIZE; i++) {
a[i] = (float)rand();
b[i] = (float)rand();
c[i] = 0.;
}
// compute c[i] = a[i] + b[i]
t_start = omp_get_wtime();
for (j=0; j<REPS; j++)
for (i=0; i<SIZE; i++)
c[i] = a[i] + b[i];
t_finish = omp_get_wtime();
t = t_finish - t_start;
printf("Run summary\n");
printf("=================\n");
printf("Array size: %d\n",SIZE);
printf("Total time (sec.):%f\n",t);
// That's it!
return 0;
}The computational environment
I use a laptop running Linux Mint 21.3 with 8GB RAM on an Intel’s Core-i7. The compiler was Intel’s OneAPI (version 2024.0.2) and Intel Advisor for measuring and visualizing the roofline. If you want to reproduce my test you need as a first step to prepare the environment as can be seen here:
$ <strong>source ~/path/to/opt/intel/oneapi/setvars.sh</strong>
# change the line above according to the path in your file system
:: initializing oneAPI environment ...
bash: BASH_VERSION = 5.1.16(1)-release
args: Using "$@" for setvars.sh arguments:
:: advisor -- latest
:: ccl -- latest
:: compiler -- latest
:: dal -- latest
:: debugger -- latest
:: dev-utilities -- latest
:: dnnl -- latest
:: dpcpp-ct -- latest
:: dpl -- latest
:: inspector -- latest
:: ipp -- latest
:: ippcp -- latest
:: itac -- latest
:: mkl -- latest
:: mpi -- latest
:: tbb -- latest
:: vtune -- latest
:: oneAPI environment initialized ::Another, one time, preparation stage is setting ptrace_scope otherwise Advisor won’t work:
$ cat /proc/sys/kernel/yama/ptrace_scope
1
$ echo "0"|sudo tee /proc/sys/kernel/yama/ptrace_scope
[sudo] password for your_user_name:
0The results
First, I tested the un-optimized version that was listed above. The measured point obtained sits at 0.028FLOP/Byte, this result is lower than the theoretical prediction and this means that we need to put more effort to improve the code. The roofline result of this un-optimized version is shown here:

One can verify that the CPU spent most of its time in the main loop:
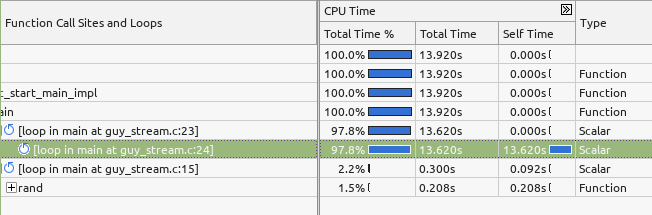
In the recommendations section Intel Advisor state: “The performance of the loop is bounded by the private cache bandwidth. The bandwidth of the shared cache and DRAM may degrade performance.
To improve performance: “Improve caching efficiency. The loop is also scalar. To fix: Vectorize the loop“. Indeed in the next step I repeat the roofline measurement but with a vectorized executable. The compilation command I used is:
icx -g -O3 -qopt-report-file=guy_stream.txt -qopenmp -o guy_stream_vec ./guy_stream_vec.cand the vectorization report says:
Global optimization report for : main
LOOP BEGIN at ./guy_stream.c (15, 1)
remark #15521: Loop was not vectorized: loop control variable was not identified. Explicitly compute the iteration count before executing the loop or try using canonical loop form from OpenMP specification
LOOP END
LOOP BEGIN at ./guy_stream.c (23, 1)
remark #15553: loop was not vectorized: outer loop is not an auto-vectorization candidate.
<strong>LOOP BEGIN at ./guy_stream.c (24, 5)
remark #15300: LOOP WAS VECTORIZED
remark #15305: vectorization support: vector length 4</strong>
LOOP END
LOOP ENDThis time the roofline plot reports on a performance improvement compared to the non-optimized code. However, in both cases the performance bottleneck is still the DRAM bandwidth, as expected. The vectorized roofline plot is shown here:
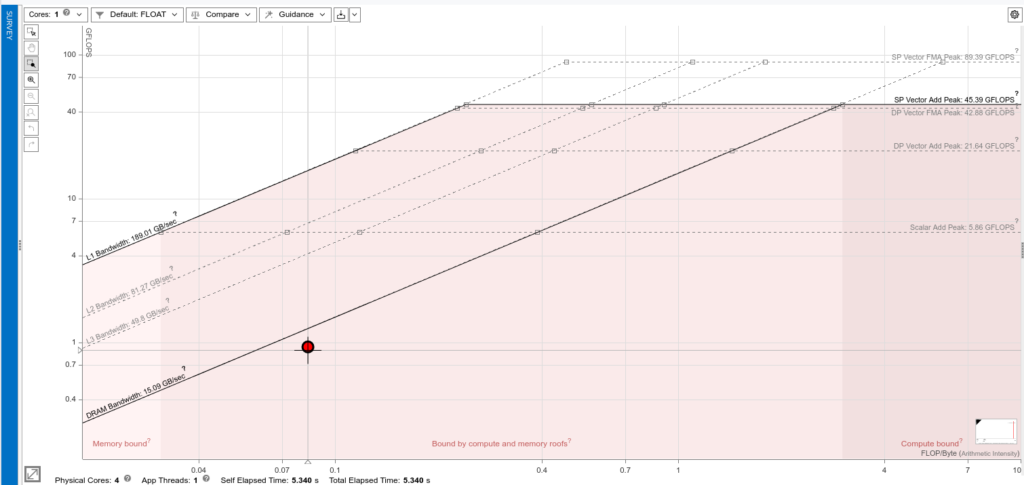
This time the performance is 0.083FLOP/Byte which is our theoretical prediction! This means that although the code hasn’t changed, the compiler managed to do the more ‘add’ instructions per unit of time, in parallel, due to the vectorization support:
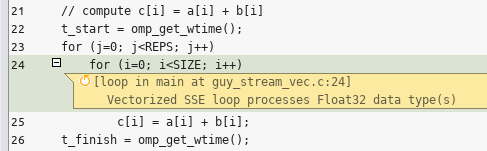
Another possible optimization one could think of is adding an alignment to the arrays in memory:
__attribute__((aligned (64)))However, adding this requirement also didn’t improve much the performance. It seems that we really reached the performance wall and the reason for that is that the bottleneck isn’t in the computation but in the DRAM bus performance.
As a last step I tried another optimization technique, which is to add multi-threading, i.e. parallelizing the code with OpenMP. Adding an OpenMP parallel-for pragma causes the computational kernel to be computed in parallel. However, once again, there wasn’t any performance improvement.
# pragma openmp parallel for
for (j=0; j<REPS; j++)
for (i=0; i<SIZE; i++)
c[i] = a[i] + b[i];To conclude, the roofline mode is a strong tool for checking where are the performance bottlenecks in the code. As long that we suffer from the limitations of the DRAM (or the caches) there isn’t much we can do about improving the performance. The CPU can ingest more operations on new data but since the memory is slow the performance are poor. Unfortunately, there is nothing we can do about it. This is a challenging issue that is pending to future computer architectures.
If you enjoyed this article you are invited to leave a comment below. You can also subscribe to my YouTube channel (@tel-zur_computing) and follow me on X and Linkedin.
References:
[1] SamueL Willias, Andrew Waterman, and David Patterson, “Roofline: An insightful Visual Performance model for multicore Architectures“, Communications of the ACM, April 2009, vol. 52, no. 4, pp 65-76.
[2] Supplementary material to [1]: https://dl.acm.org/doi/10.1145/1498765.1498785#sup
[3] Stream, https://www.cs.virginia.edu/stream/ref.html